Mein persönlicher Messerundgang auf der diesjährigen Cebit.

Foto: Pascal Ballottin/Pixelio
Das Internet ist zwanzig Jahre alt. Aber wie groß ist es eigentlich? Eine obskure amerikanische Quelle gibt an, dass das Internet heutigen Tags exakt 1 Milliarde Seiten aufweise. Eine solche Gotteszahl können sich deutsche Redaktionen nicht entgehen lassen:
„Das Internet hat mehr als eine Milliarde Webseiten“ (Stern)
„Internet-Statistiken: 1 Milliarde Websites online“ (Giga)
„Internet knackt die Zahl von einer Milliarden Seiten“ (sic!)(Handelszeitung)
„Über eine Milliarde Websites online – Internet so groß wie nie zuvor“ (ntv)
Nachgerechnet oder gar recherchiert hat allerdings aus diesen und vielen anderen Redaktionen, die diese Zahl kolportierten, niemand. Dabei macht nicht nur die (sehr geringe) Zahl skeptisch, sondern auch die Frage, wonach hier eigentlich gefragt wird: Einzelne aufrufbare Seiten im World Wide Web? Einzelne Domains? Domains mit ihren Subdomains? Je nach dem, wonach exakt gefragt wird, kommen extrem unterschiedliche Zahlen heraus.
Der Internet-Suchgigant Google hat bereits im Jahr 2008 im hauseigenen Blog erklärt, mehr als 1 Billionen Websites indiziert zu haben. Fortan gab Google gar nicht mehr erst Auskunft darüber, um wieviele Seiten der Index zugelegt hat. Eine kleine Probe aufs Exempel kann jeder Google-Nutzer machen, indem er einfach das Wort „Google“ googelt:
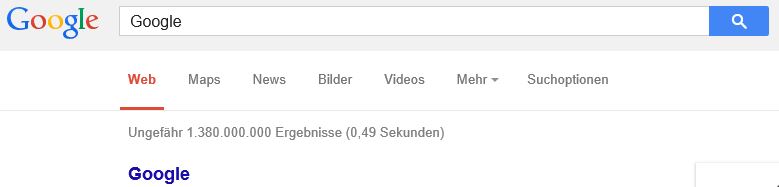 Allein Webseiten, auf denen das Wort „Google“ vorkommt, gibt es also laut Google schon deutlich mehr als eine Milliarde. Die Computerschool hat in einer hübschen Visualisierung aufgemalt, für wie groß sie alleine Google hält — auch dabei kommen Zahlen heraus, die die „1-Milliarde-Legende“ ziemlich relativieren. Demnach soll es im Jahr 2010 schon mehr als 40 Milliarden Webseiten gegeben haben.
Allein Webseiten, auf denen das Wort „Google“ vorkommt, gibt es also laut Google schon deutlich mehr als eine Milliarde. Die Computerschool hat in einer hübschen Visualisierung aufgemalt, für wie groß sie alleine Google hält — auch dabei kommen Zahlen heraus, die die „1-Milliarde-Legende“ ziemlich relativieren. Demnach soll es im Jahr 2010 schon mehr als 40 Milliarden Webseiten gegeben haben.
Kevin Kelly, einer der Gründer des Wired Magazine, geht davon aus, dass es mindestens eine Billion Internetseiten gibt. Bemerkenswert ist das für Kelly deswegen, weil das menschliche Gehirn „nur“ 100 Milliarden Neuronen aufweise, die miteinander vernetzt seien. Allerdings:
Während eine Website im Schnitt mit 60 anderen Sites vernetzt ist, kann das menschliche Gehirn das Hundertfache an Links vorweisen. Aber, so wendet Kelly korrekterweise ein, “ein Gehirn verdoppelt nicht alle paar Jahre seine Größe”.
Die gemeinnützige Stiftung des WWW-Erfinders, Tim Berners-Lees World Wide Web Foundation, soll für Klarheit sorgen: Google gibt eine Million Dollar dazu, damit die Stiftung die Größe des Internets mit einiger Zuverlässigkeit ermittelt. The Web Index heißt dieses Projekt. Es könnte sich aber als Sysiphos-Projekt entpuppen. Denn die zahlenmäßige Größe des exponentiell wachsenden Internets lässt sich womöglich aus systematischen Gründen gar nicht genau angeben. Denn große Teile des Internets sind mit herkömmlichen Methoden, also zum Beispiel mittels Suchmaschinen, gar nicht auffindbar und darum auch nicht zählbar. Dieser Teil des Internet wird auch als „deep web“ oder als „invisible web“ bezeichnet. Dazu zählen nicht nur solche Internetseiten, die sich in Anonymisierungsnetzwerken wie TOR verstecken. Auch dynamische Webseiten, die sich erst nach Nutzereingaben aufbauen (zum Beispiel Datenbanken), können nicht recht mitgezählt werden. Es gibt Stimmen, die behaupten, dass dieses „deep web“ um den Faktor 400 bis 550 größer sei als das „visible web“.
Egal, wieviele Internetseiten es gibt, 1 Milliarde Seiten sind es mit recht großer Sicherheit nicht. Noch stutziger hätte einen eine weitere Angabe in der hauptsächlich von der Nachrichtenagentur AFP verbreiteten Nachricht machen:
Nach Angaben von internetlivestats.com gingen allein am Dienstag 3,1 Milliarden Suchanfragen bei Google ein.
Denkt man beide Zahlen zusammen, bedeutet das, dass nach jeder einzelnen der angeblich 1 Milliarde Internetseiten dreimal täglich gesucht würde. Dass es dreimal mehr Suchanfragen als Internetseiten geben soll, ist auch nicht recht plausibel. Ein bisschen Recherchieren oder einfach ein bisschen Nachdenken hätten gereicht, um eine solche Ente nicht zu verbreiten.
Das Recht auf Vergessen hat der Europäische Gerichtshof den Google-Usern zuerkannt. Die Suchmaschinenfirma Google setzt dieses Urteil jetzt um. Es hat ein Webformular ins Netz gestellt, auf dem man die Entfernung aus den Suchergebnissen gemäß Europäischem Datenschutzrecht beantragen kann. Gründe muss man nicht anführen, wenn man will, dass bestimmte URLs aus den Trefferlisten gelöscht werden. Allerdings muss man ein Abbild seines Personalausweises hochladen, um sich eindeutig zu identifizieren.

Auf der Crowdfunding-Plattform Krautreporter sammelt der Autor und Journalist Christian Jakubetz für einen Sammelband zur digitalen Zukunft des Journalismus mit einer illustren Autor/innen-Schar. Schon der erste Band war (nachdem die üblichen Fachverlage abgesagt hatten) auf ähnliche Weise finanziert worden und ein großer Erfolg — jedenfalls war das Buch in kurzer Zeit ausverkauft. Also, spenden, sammeln, lesen und klug werden!
Im zweiten Band soll beleuchtet werden, wo die vorgebliche Krise des Journalismus herkommt, ob journalistisches Schreiben und Erzählen auch künftig eine Chance hat und ob Journalismus ein Beruf bleiben wird, der Spaß machen kann.
 Der amerikanische Geheimdienst NSA guckt anderen gerne in die Karten, selbst lässt er sich aber äußerst ungern ins Blatt schauen. Im vergangenen Jahr allerdings mussten die NSA-Agenten aufgrund des amerikanischen Informationsfreiheitsgesetzes ein spannendes Dokument der Öffentlichkeit zur Verfügung stellen: „Untangling the Web – A Guide to Internet Research“ ist ein Handbuch für Internetrecherchen, in dem man nachlesen kann, wie amerikanische Spione googlen sollen. Es finden sich aber auch Hack-Tricks für Yahoo und andere Suchmaschinen.
Der amerikanische Geheimdienst NSA guckt anderen gerne in die Karten, selbst lässt er sich aber äußerst ungern ins Blatt schauen. Im vergangenen Jahr allerdings mussten die NSA-Agenten aufgrund des amerikanischen Informationsfreiheitsgesetzes ein spannendes Dokument der Öffentlichkeit zur Verfügung stellen: „Untangling the Web – A Guide to Internet Research“ ist ein Handbuch für Internetrecherchen, in dem man nachlesen kann, wie amerikanische Spione googlen sollen. Es finden sich aber auch Hack-Tricks für Yahoo und andere Suchmaschinen.
Die amerikanische Computerzeitschrift Wired hat einen interessanten Artikel zum Thema ins Netz gestellt:
Wired — Use These Secret NSA Google Search Tips to Become Your Own Spy Agency
Im deutschen Sprachraum hat der österreichische Standard das Dokument bekannt gemacht:
Standard.at — Geheimes NSA-Handbuch für Internet-Recherchen veröffentlicht
Was einen bei der Lektüre von „Untangling the Web“ stutzig macht, ist die Tatsache, wie simpel es zum Teil ist. Nun ist das Handbuch sieben Jahre alt und darum nicht mehr ganz up-to-date, aber selbst dann darf es nicht als sensationelle Enthüllung gelten. Die Agenten des NSA machen es eben auch nicht anders als alle anderen: Suchbegriffe eingeben und warten, was passiert. Das korrespondiert durchaus mit anderen Beobachtungen, die man im Zuge der Prism-Enthüllungen machen konnte: Die NSA kann zwar prinzipiell alles herausfinden, konkret aber hat sie offenbar trotzdem nicht allzu viel herausgefunden. Den Nachweis, dass durch den ungeheuerlichen Spionageaufwand irgend ein Verbrechen verhindert oder aufgeklärt worden wäre, ist die amerikanische Agentur schuldig geblieben — ein Umstand, der in der amerikanischen Gesellschaft sehr kontrovers diskutiert wird, schließlich muss sie für diesen Aufwand bezahlen.
Es gibt durchaus einige spitzfindige Recherchetipps in „Untangling the Web“. Aber prinzipiell kann man wirklich besser googlen, als es der amerikanische Geheimdienst macht.
Diäten beginnen im Kopf. Nirgends wird das deutlicher, als bei diesem auf Facebook gefundenen Posting, das mit „suggested post“ nur unzureichend als Werbung kenntlich gemacht wurde:
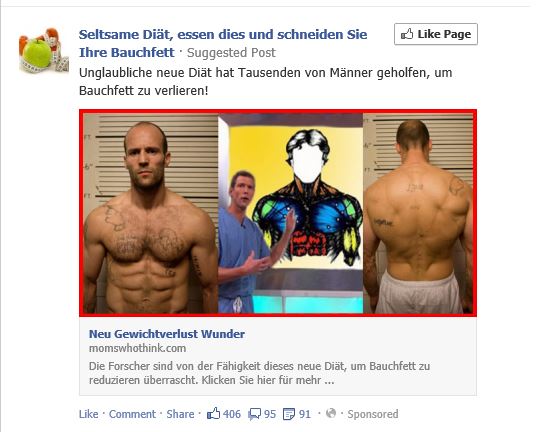
Facebook-Screenshot
Was sie wohl meine tun mit „Seltsame Diät, essen dies und schneiden Sie Ihre Bauchfett?“ Sie tun meinen vielleicht, wer wenig essen, der auch wenig Sauerstoff im Kopf? Oder, wie tut zeigen dieser Grafik in der Mitte, dass Vorurteil doch stimmt: Viel Muskeln unternrum, aber dafür nix im Hirn? Weiter heißt es: „Die Forscher sind von der Fähigkeit dieses neue Diät überrascht“. Ich bin’s auch und kratze mir mit wenig Muskelaufwand am Hirn. Es wird vielleicht doch mal Zeit für eine Mediendiät. Diäten beginnen eben im Kopf.
Was man nicht alles herunterladen kann! Jetzt sogar volljährige Kinder:
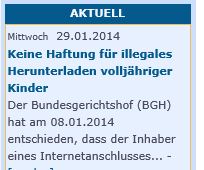 Gesehen auf der Website einer Kölner Anwaltskanzlei.
Gesehen auf der Website einer Kölner Anwaltskanzlei.
Auch Zukunftskonzerne verheddern sich manchmal in der Vergangenheit. So geschah es jetzt dem Kartendienst Google Maps: Der Theodor- Heuss-Platz im Berliner Stadtteil Wilmersdorf heißt bei Google Adolf-Hitler-Platz:
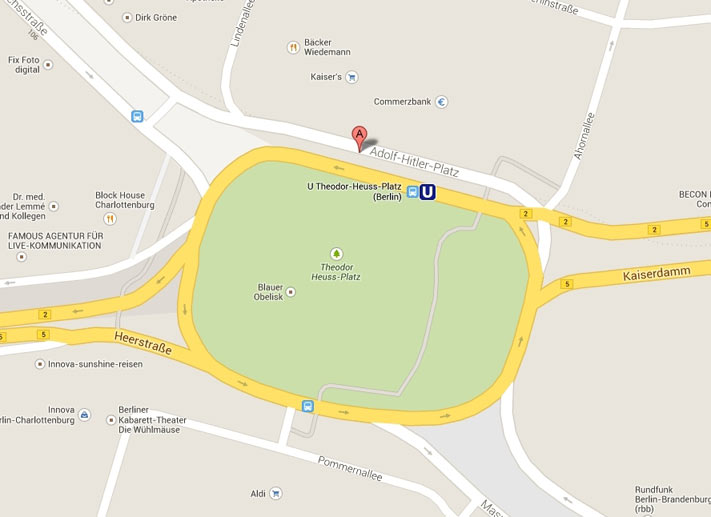
Screenshot: Google Maps vom 09.Januar 2014
Stern.de erklärt den historischen Hintergrund:
Der Theodor-Heuss-Platz wurde am 18. Dezember 1963 – wenige Tage nach seinem Tod – nach dem ersten Bundespräsidenten benannt. Von 1906 bis 1933 und von 1947 bis 1963, also vor und nach der Zeit des Nationalsozialismus, hieß der Platz Reichskanzlerplatz.
Mittlerweile hat Google die Panne korrigiert. Wie es zu dem Fehler kam, kann der US-Internetkonzern nicht erklären.
BBC-Reporter Simon McCoy stand vielleicht ein bisschen neben sich, auf jeden Fall griff er kräftig daneben: Statt des bereitliegenden iPads griff der Nachrichtensprecher sich einen Packen Kopierpapier und moderierte mit dieser Ausstattung die BBC News an. Dabei ging es in seiner Moderation ausgerechnet um Ausnüchterungszellen:
http://youtu.be/8MouaeygJe4
In den sozialen Netzwerken gehen die Meinungen über den ungewöhnlichen Auftritt auseinander: Die einen begrüßen die Rückkehr zu analogen Medien wie dem Papier. Andere machen sich eher lustig über die „Mutter aller öffentlich-rechtlichen Rundfunkanstalten“:
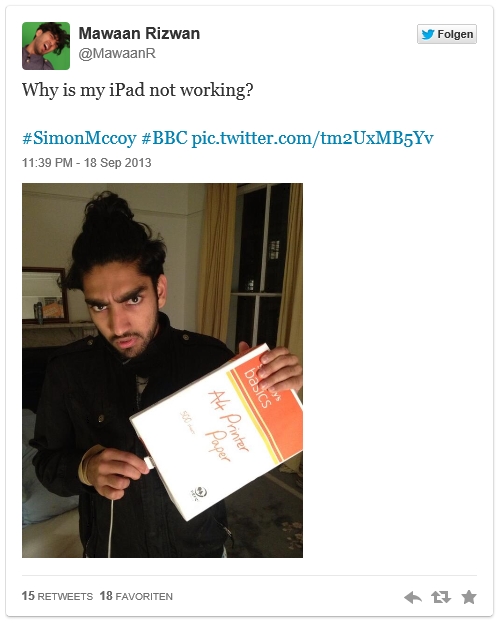
Der Fernsehblog der Süddeutschen Zeitung verweist darauf, dass dies nicht die erste Panne von McCoy live im Fernsehen sei. Erst im vergangenen Jahr sei er mit dem Kopf vom Studiotisch hochgeschreckt, als ob er gerade ein Nickerchen gemacht hätte.
Im Live-Geschäft des Fernsehens kommt es immer mal wieder zu Pannen. Besonders interessant, da im deutschen Wahlkampf ja gerade eine Stinkefinger-Diskussion uns im Atem hält, ist der Fall des BBC-Wetteransagers Tomasz Schafemaker, der unversehens eben jenen gestreckten Mittelfinger auspackte, als er eigentlich mit seiner Moderation beginnen sollte:
Die journalistische Notfallpraxis im Web von Hektor Haarkötter